LangExtract
综合介绍
LangExtract是一个由Google开发的Python库,它利用大语言模型(LLM)从非结构化文本文档中提取结构化信息。用户只需通过简单的指令和几个示例来定义提取任务,该工具就能处理各类文本,例如临床笔记、法律文件或文学作品。其核心特色在于能够将提取出的每一条数据精确地映射回原文的具体位置,确保了信息的可追溯性和准确性。LangExtract还优化了对长文档的处理,通过文本分块、并行处理和多遍提取策略,解决了在海量信息中准确定位“大海捞针”的难题。此外,它能生成一个独立的、可交互的HTML文件,用于在原始上下文中可视化地审查提取结果。该库支持多种语言模型,包括云端的Gemini系列和本地部署的开源模型,使其能够灵活适应不同领域和规模的提取需求,无需对模型本身进行微调。
功能列表
- 精确定位来源: 将每一个提取出的信息与它在源文本中的确切位置进行映射,方便用户通过可视化高亮来追溯和验证。
- 可靠的结构化输出: 根据用户提供的少量示例,强制执行一致的输出格式,确保结果的稳定和可靠。
- 优化长文档处理: 采用文本分块、并行处理和多遍扫描的策略,有效处理长篇文档,提高了信息提取的召回率。
- 交互式可视化: 可以生成一个独立的HTML文件,用户能够在这个文件中交互式地查看和审核提取出的成千上万个实体及其上下文。
- 灵活的LLM支持: 支持多种语言模型,包括Google Gemini系列,也内置了对Ollama的接口,可以方便地使用本地开源模型。
- 适应任何领域: 用户只需提供几个示例即可定义任何领域的提取任务,无需微调模型,工具就能适应特定需求。
- 利用LLM世界知识: 允许用户通过精确的提示词和示例,来引导模型利用其已有的知识进行推理和提取。
使用帮助
LangExtract是一个功能强大的Python库,旨在帮助用户从非结构化文本中轻松提取出有组织、有结构的数据。下面将详细介绍如何安装和使用这个工具。
安装
为保证项目环境的纯净,推荐使用Python虚拟环境。
- 从PyPI安装(推荐)这是最简单的安装方式,适用于绝大多数用户。
# 创建并激活虚拟环境 (macOS/Linux) python -m venv langextract_env source langextract_env/bin/activate # 在Windows上激活 # langextract_env\Scripts\activate # 安装库 pip install langextract - 从源代码安装如果你希望修改源代码或进行二次开发,可以选择此方式。
# 克隆GitHub仓库 git clone https://github.com/google/langextract.git cd langextract # 安装为可编辑模式,这样你的修改会立刻生效 pip install -e . # 如果需要安装开发或测试依赖 # pip install -e ".[dev,test]"
API密钥设置
当使用像Gemini这样的云端托管模型时,你需要配置API密钥。如果你使用本地模型(如通过Ollama运行),则无需此步骤。
- 方式一:环境变量(推荐)在你的终端中设置一个环境变量,这是最安全和灵活的方式。
export LANGEXTRACT_API_KEY="你的API密钥" - 方式二:
.env文件在你的项目根目录下创建一个名为.env的文件,并将密钥写入其中。LangExtract会自动加载。LANGEXTRACT_API_KEY=你的API密钥 - 方式三:直接在代码中提供此方法不推荐用于生产环境,因为它会将密钥硬编码在代码中,但对于快速测试很方便。
result = lx.extract(..., api_key="你的API密钥")
操作流程:快速上手
下面通过一个简单的例子,演示如何从一段文本中提取角色、情感和关系。
第一步:定义提取任务和规则
首先,你需要明确告诉模型你想要提取什么。这通过一个清晰的prompt(提示)和一些高质量的examples(示例)来完成。
import langextract as lx
import textwrap
# 1. 定义描述任务的提示
# 告诉模型需要提取哪些内容,遵循什么规则
prompt = textwrap.dedent("""\
按出现顺行提取角色、情感和关系。
提取时请使用原文中的确切文本。
不要转述或重叠实体。
为每个实体提供有意义的属性以增加上下文信息。""")
# 2. 提供一个高质量的示例来指导模型
# 示例包含一段文本和这段文本中已经提取好的结构化信息
examples = [
lx.data.ExampleData(
text="罗密欧:轻声!那边窗户里透出来的光是什么?那就是东方,朱丽叶就是太阳。",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="罗密欧",
attributes={"emotional_state": "惊奇"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="轻声!",
attributes={"feeling": "温柔的敬畏"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="朱丽叶就是太阳",
attributes={"type": "隐喻"}
),
]
)
]
第二步:运行提取
将你的输入文本、任务提示和示例一起传递给 lx.extract 函数。
# 需要处理的输入文本
input_text = "朱丽叶小姐凝视着星星,她的心为罗密欧而痛"
# 运行提取过程,这里使用性价比较高的 gemini-1.5-flash 模型
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-1.5-flash",
)
# 打印提取结果
for extraction in result.extractions:
print(extraction.model_dump_json(indent=2))
模型会根据你的指令和示例,从input_text中找到符合条件的信息并结构化输出。
第三步:可视化结果
LangExtract最强大的功能之一就是可视化。你可以将结果保存为.jsonl文件,然后生成一个交互式的HTML报告。
# 将结果保存为JSONL文件
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
# 从JSONL文件生成HTML可视化内容
html_content = lx.visualize("extraction_results.jsonl")
# 将HTML内容写入文件
with open("visualization.html", "w", encoding="utf-8") as f:
f.write(html_content)
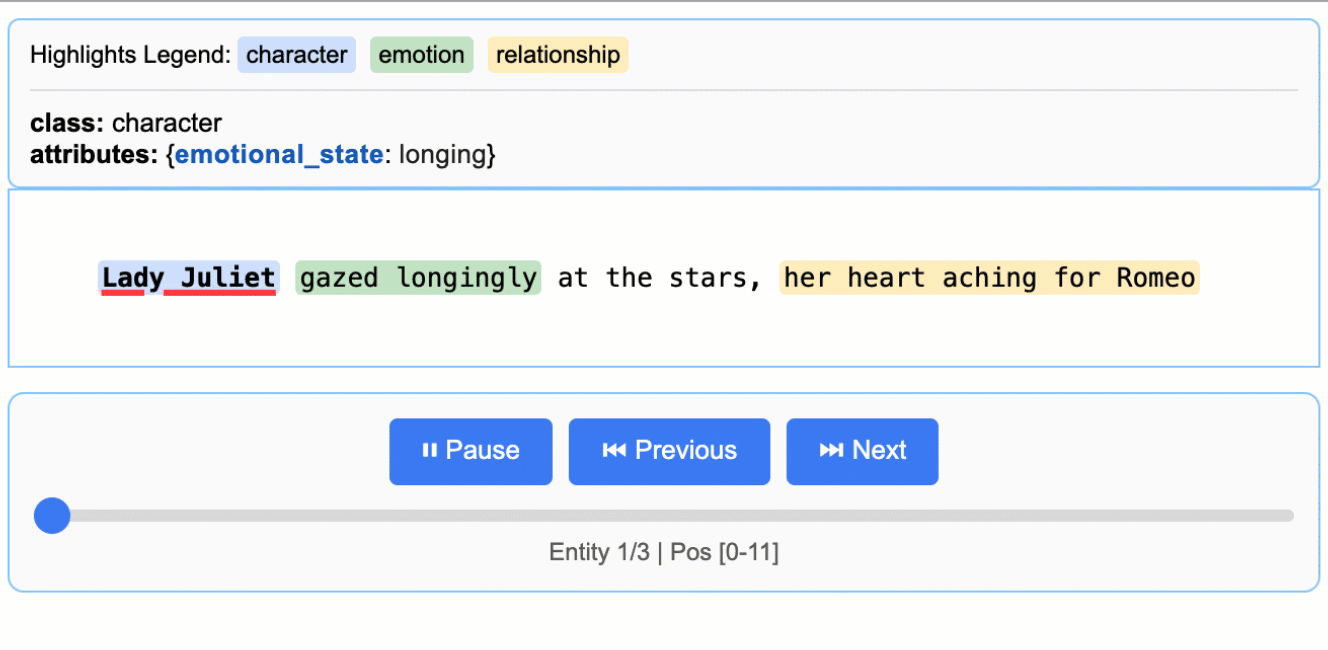
打开生成的visualization.html文件,你将看到一个交互式界面。当鼠标悬停在提取出的实体上时,它会在左侧的原文中高亮显示,让你能够直观地检查提取的准确性。
应用场景
- 文学作品分析可以自动从小说、剧本等长篇文本中提取人物、情节、地点、人物关系和情感线索,帮助研究人员或读者快速梳理文本结构,进行文学分析和角色研究。例如,可以完整处理《罗密欧与朱丽叶》全文,提取数百个实体并进行可视化。
- 医疗信息结构化从病历、出院小结、放射学报告等非结构化临床文本中,精确提取药物名称、剂量、用法、检查结果和诊断等关键信息。这有助于将医疗记录转化为结构化数据,用于后续的临床研究或数据分析。例如,RadExtract项目就展示了如何使用LangExtract自动解析放射学报告。
- 法律和商业文档审查在合同、财报、法律文书等文件中,自动识别并提取关键条款、合同方、金额、日期和责任规定。这可以极大提高律师、会计师和商业分析师的工作效率,减少人工审查中的疏漏。
- 通用知识提取由于其高度的灵活性,LangExtract可以应用于任何需要从文本中提取特定信息的领域。用户只需提供符合自己需求的指令和几个示例,就可以为特定任务(如新闻事件提取、产品评论分析、简历信息解析等)定制提取器,而无需进行复杂的模型训练。
QA
- LangExtract是什么?LangExtract是一个Python库,它使用大语言模型(LLMs)根据用户定义的指令,从非结构化文本(如报告、文章或笔记)中识别和提取结构化信息,并能将提取结果精确地映射回原文位置。
- LangExtract是Google的官方产品吗?不是。这是一个由Google员工开发的开源项目,但它并非Google官方支持的产品。使用时需遵守Apache 2.0许可证。
- LangExtract支持哪些语言模型?它支持多种模型,包括云端的Google Gemini系列(如gemini-1.5-flash和gemini-1.5-pro),并且内置了对Ollama的接口,可以方便地连接和使用本地运行的开源大语言模型。
- LangExtract如何处理非常长的文档?对于长文档,LangExtract采用了一种优化的策略,包括将文本智能地分割成小块、并行处理这些文本块以提高速度,以及执行多遍提取来提升召回率。这种方法能有效解决在大型文档中提取信息的“大海捞针”问题。